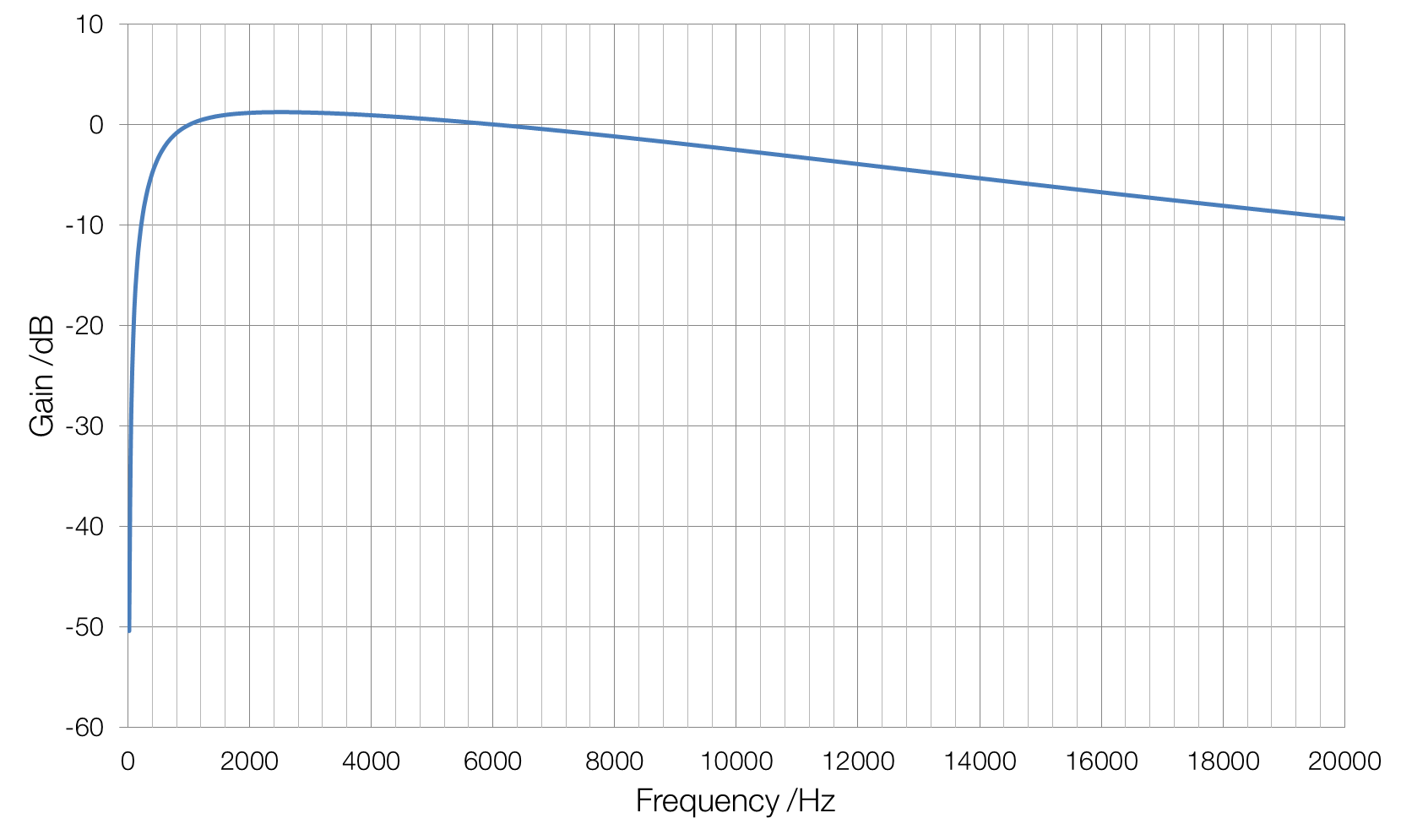
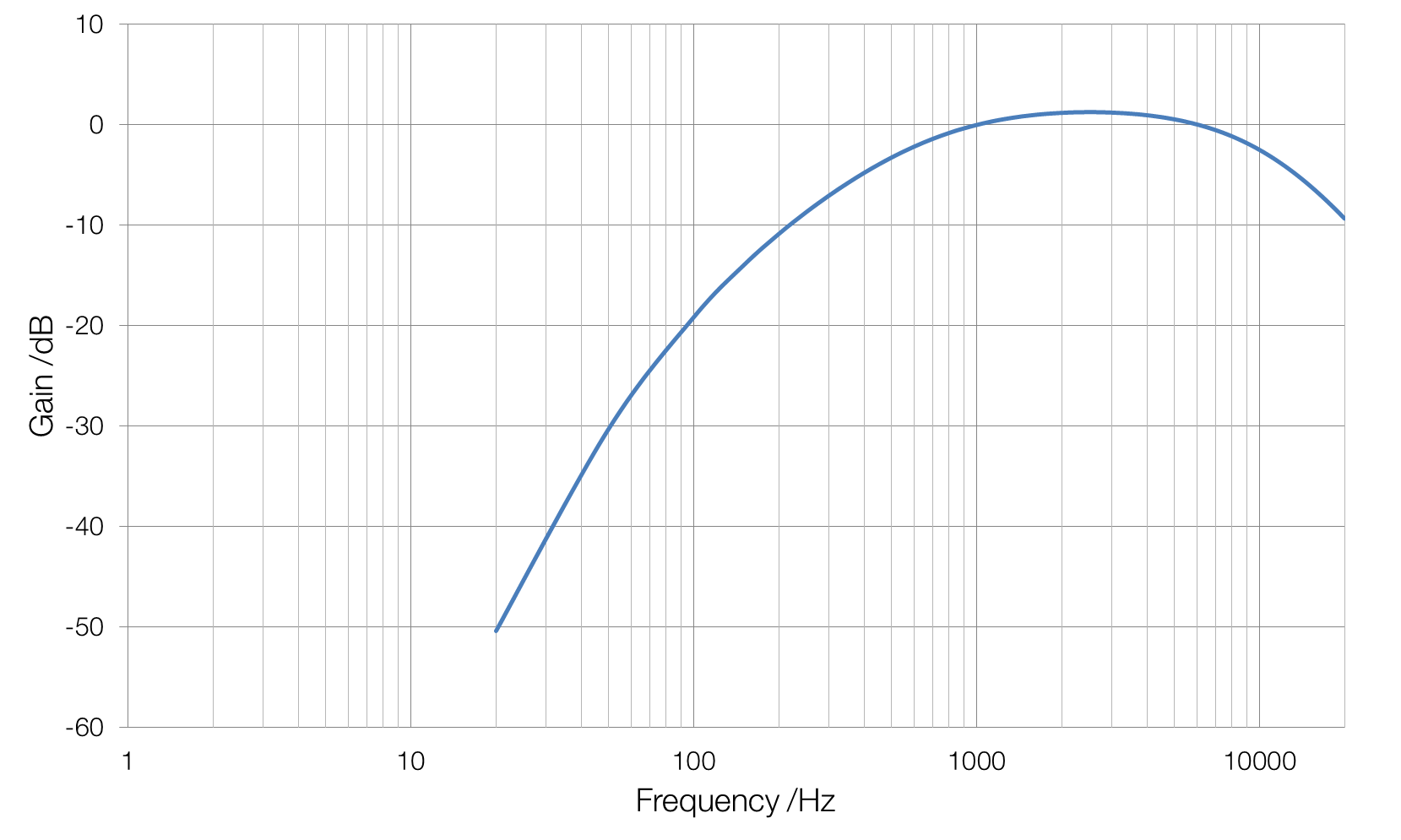
Sound is created by vibrating objects. As an object, such as a loudspeaker’s diaphragm moves back and forth it compresses the air, causing changes in pressure. These changes in pressure cause your eardrum to move back and forth and these back-and-forth movements are translated by your brain into sound. Larger, louder, movements cause greater changes in pressure.
 A tuning fork creates compressions (higher pressures) and rarefactions (lower pressures) in the air.
A tuning fork creates compressions (higher pressures) and rarefactions (lower pressures) in the air.
The human ear is incredibly good at detecting changes in air pressure; it can detect the greatest range of stimuli of all your senses. The quietest sound that the ear can hear is the smallest change in pressure that it can detect: 20 µPa, less than a billionth of atmospheric pressure. To calculate the volume of a sound you must compare the pressure change caused by the sound with this smallest detectable change.

The decibel* scale is logarithmic. One bel represents a tenfold increase in pressure so a 50 dB sound is ten times louder than a 40 dB sound. The average volume of human speech is about 60 dB and the threshold of ear pain is 130 dB, some 107 or ten million times louder.
Because a sound wave consists of alternating low and high pressures there comes a point at which the sound is so loud that the rarefaction (low) pressure is the lowest possible pressure: a vacuum at 0 Pa. This corresponds to a compression pressure of one atmosphere or 101325 Pa. If we put these figures into the equation for volume we find:


So there you have it: the loudest possible sound is 194 dB. It has often been said that the loudest ever recorded sound was the eruption of Krakatoa in 1883 which was heard from nearly 5000 km away. The pressure wave created by the eruption was measured to be at least 20000 Pa, equivalent to a volume of 180 dB, 101.4 or twenty-five times quieter than the loudest possible sound.
* The prefix deci- indicates a tenth.