From the always-excellent Futility Closet, a problem by Paul J. Nahin:
Each of a million people puts his or her hat into a very large box. Each hat has its owner’s name on it. The box is given a good shaking, and then each person, one after another, randomly draws a hat out of the box. What is the probability that at least one person gets their own hat back?
Most people might think that the chance is very, very small, but it’s not. It’s actually more than 60%. How can this be true?
We can view this problem as having only two possible solutions (events): either nobody gets their hat back, or at least one person gets their hat back. The sum of the probabilities of these events must be equal to one and therefore if we can work out the probability that nobody gets their own hat back, then the probability that at least one person does is one minus that.
For each person, there is only a one-in-a-million chance that they have picked their own hat, and thus a 999999 in 1000000 chance that they have not got their own hat.


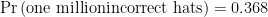
If the probability of all one million people picking the incorrect hat in 0.368, then via our previous reasoning, the probability of at least one person picking the correct hat is 1-0.368, or 63.2%.
This is a very counterintuitive result, but the wording of the question is key. If we changed the wording to exactly one person getting their hat back then our answer changes dramatically. Starting with our 63.2% chance, we would have to subtract the chance of two people getting their hats back, and of three people getting their hats back, and so on … until we reached the very small chance of one person, and one person only, getting their hat back.